



Samples from our model, 4DiM, all generated from a single input image.
We present 4DiM, a cascaded diffusion model for 4D novel view synthesis (NVS), supporting generation with arbitrary camera trajectories and timestamps, in natural scenes, conditioned on one or more images. With a novel architecture and sampling procedure, we enable training on a mixture of 3D (with camera pose), 4D (pose+time) and video (time but no pose) data, which greatly improves generalization to unseen images and camera pose trajectories over prior works that focus on limited domains (e.g., object centric). 4DiM is the first-ever NVS method with intuitive metric-scale camera pose control enabled by our novel calibration pipeline for structure-from-motion-posed data. Experiments demonstrate that 4DiM outperforms prior 3D NVS models both in terms of image fidelity and pose alignment, while also enabling the generation of scene dynamics. 4DiM provides a general framework for a variety of tasks including single-image-to-3D, two-image-to-video (interpolation and extrapolation), and pose-conditioned video-to-video translation, which we illustrate qualitatively on a variety of scenes.
Below we show 4DiM samples on unseen RealEstate10K input images:
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show zero-shot 4DiM samples on the Local Light Field Fusion (LLFF) dataset:
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show zero-shot 4DiM samples on arbitrary images gathered from the internet:
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show 4DiM samples on video interpolation, i.e., given the first and the last frame, 4DiM generates a video in between them. There is no camera pose input.
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show 4DiM samples on video extrapolation, i.e., given the first two frames, 4DiM generates the rest of the video. There is no camera pose input.
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show zero-shot 4DiM samples on pose-conditional 8-frame video to 8-frame video translation. Here, we focus on camera stabilization, i.e., given a video with a moving camera, 4DiM generates a video with dynamics but sets the camera at a fixed position.
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Here, we focus on novel trajectory generation, i.e., given a video with a moving camera, 4DiM re-generates a video with the camera moving along the newly desired trajectory.
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Below we show 4DiM samples on the more challenging case of 360° camera rotation:
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Generating 4D from a single image is extremely challenging. Here we show a driving scene where we advance in both space and time from a single starting image:

We show another example of long trajectory generation. Interestingly we find that the trajectory influences the scene content (curved road).
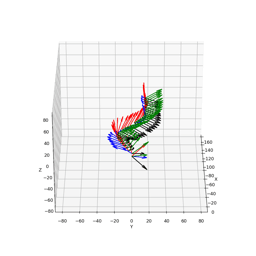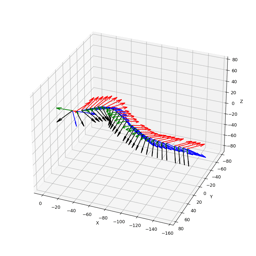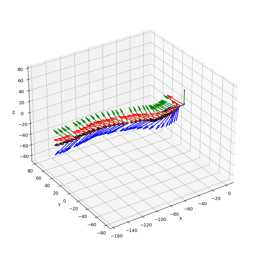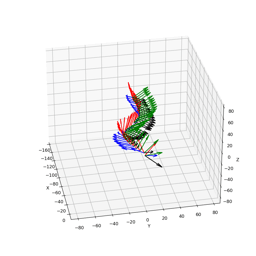

4DiM can stitch 360° panoramas without the exposure artifacts found in traditional stitching methods. Here we show a comparison of 4DiM v.s. homography with gamma adjustment, given six input images:



One particular application of video-to-video translation is to adjust camera orientations. Here we simultaneously generate increasingly larger angle changes to a side-view camera to make it look to the front.



Latent diffusion: at the time of writing, 4DiM was developed on a cascaded pixel space pipeline, but our techniques fully translate to LDMs. Below we show 512x512 results from a latent 4DiM model:
 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

 ⟶
⟶

Co-training with video: we include some side-by-side comparisons of 4DiM v.s. 4DiM trained without large-scale unposed video on LLFF to show the impact on OOD generalization:












Comparison other frame interpolation methods: we include some side-by-side comparisons of 4DiM v.s. various video interpolation methods from prior work on the Davis dataset (FILM, RIFE, LDMVFI):































